












What is the medium of AI art?
May 2023AI art tools are way, way cooler than you think they are. But there are two factors at play preventing the general public and visual artists from correctly assessing the coolness of these tools. The first is common to all machine learning applications. We’ve recently seen major breakthroughs in the development of the underlying ‘base’ models that all this new AI stuff is built on, but our understanding of how to actually use these models lags far behind how capable they are. The second is simply that because machine learning is a technical field, getting a better understanding of these tools is tricky. I’m sure both of these factors will change in not too long, considering that these models haven’t even been around for a full year. But a big part of why I’m writing this article is to hopefully encourage the involvement of visual artists.
In the next few years machine learning tools are going to catalyse a tremendous growth in knowledge across diverse fields. But the people leading this discovery and creation of knowledge aren’t going to be the actual machine learning engineers. Rather, it’ll be the domain experts who apply these new tools to their respective fields. Art isn’t going to be any different, except for that artists are the highly-specialized domain experts of fields of their own invention. Each of us has spent our time developing a highly specific knowledge, not always that visible to others.
For us to get the tools specific to the needs of our own methods of knowledge creation, we’re probably going to have to get involved. The tools that are available today are not being built with visual artists in mind. The more that we explore the potential of these tools, the more we will be able to contribute to their development and the more we will be able to use them to explore our own artistic universes.
Disclaimer! I’m an artist. These are my interpretations of the technical concepts that I’m learning about, and which are still very new to me. So bear that in mind if you find yourself at a dinner party full of hardcore machine learning practitioners.
A medium holds an impression of us
Imagine pressing your fingers into a clump of clay. As you press in, you form indentations, which record the path that your fingers took and how the clay reacted to the force of your fingers along this path. We can even read into this record more than just what physically took place. It’s obvious to us that a person made them, and maybe we can even sense what the person’s state of mind was at the time of the act. Did you squeeze with all their might or press lightly as though just testing it?
We use mediums like clay to create these records of ourselves. These first finger indentations hold a record of the act of finger-pressing that caused them, but they quickly get lost as future actions leave their own impression on the clay. By the end of the process we could end up with an object with no noticeable trace of any one of the individual actions that led to its finished state. The impression that holds through this process is not necessarily the physical actions that we apply to the medium, but more of ourselves, the person performing those actions.
A medium enables us to manifest something about ourselves into tangible form. The process is guided by the decisions we make along the way, which are informed by the things that provide insight into our individual nature, like our tastes and preferences, how we feel and how we see the world and our place in it.
Machine learning models as a medium
Machine learning models like the ones that make AI art are trained on massive datasets of text-image pairs. Each of these images and their accompanying text description are records of individual actions. Though each of these records are of a set of human actions, it is the context in which these actions took place that is helpful to the model achieving its training objectives. These are things like if the image is a photo, what that photo is of, why a person would take that photo and why that photo looks the way it does. And crucially, why that photo was described in the specific way it was, what this implies about how we use text to describe our visual world and what this says about our world.
All of this context is read into these records from the patterns that occur in the arrangement of pixels that make up each individual image and the combination of letters and other text characters that make our descriptions of them. Though each image-text pair was created in its own unique context, into which they only provide a slight insight, the overlaps between these different contexts are what the broader idea of our visual universe is made up of. Though the patterns of pixels and text characters that make up each pair imply only that pair’s individual and highly-opinionated view of the world, the overlaps between these views reveal the shared framework that we use to create imagery.
The final form of a clay object is formed by many individual indentations, each from a different direction and often contradicting those that came before it. It holds an impression primarily of the guiding force behind all of these indentations, us expressing ourselves. Similarly, the final form of a machine learning image model was shaped by the individual pressures exerted by each of the image-text pairs in its training dataset. But the record that is created is not of these individual impressions, but of the guiding force behind them.
Compression
One way of thinking about how a model like Stable Diffusion learns to create images, is that it learns how to compress images into tiny versions of themselves, that it is able to decompress back into its image form. The image files we use to store and display images act as a map of which colour pixels need to go where, but the form of these images resulting from being compressed by the model are coordinates to a map within the model. The model essentially maps out all of the features that typically make up images. The compressed form of an image is essentially a set of coordinates, pointing to where on this map you will find the combination of features that make up that image.
This compressed form is known as a ‘latent’ image. The term implies that these images are in their potential form, rather than in their ‘actual’ visible form.
Of course the model can’t just look at the picture to work out what visual features it is made up of. Rather, it finds these features in the patterns that occur in the numeric values that indicate the colour of each pixel. You could also think of these patterns as rules. These are the rules that determine how different colour pixels are combined together to form images. The rules govern not only the basic physical features that make up images, but also how these basic features are combined to form the complex visual features that informs our semantic understanding of the meaning of an image, whether this is its subject matter or the overall mood that it conveys.
In a sense, a machine learning model is a collection of rules that when applied to an input, results in the desired output. In our case, the model is the set of rules required to take as an input the highly compressed record of which features make up an image, and return the decompressed image as an output. In order for the model to be able to compress images and then decompress them back into their original form, the rules that make it up need to resemble the ones that actually do govern how we express ourselves visually.
Decompressing text into images
The most common way of using generative image models is by inputting text. This means that the model generates an image by decompressing the text input. This is possible because of a really nifty trick in the model’s design. The text given to the model is first compressed, according to a different set of rules from the ones used to compress and decompress images. Even though two totally different rulesets govern these two different domains, a ‘contrastive’ training approach was used to align them. Literally, this means that the actual bunch of numbers that record the location of a latent image, or in other words that record which features make it up, are very similar to the actual bunch of numbers that record the location of latent string of text in the text map.
*You can find out more in my other article Exploring Diffusion Models, in the CLIP models section.
This allows the model to simply compress the text using the text-compression ruleset and decompress it using the image-decompression ruleset. Though text can’t address the bulk of what makes an image look the way it does, the model simply applies its rules, which invent the details just as it would for a decompressed image. The difference being that the compressed form of the image (the latent image) records a very specific configuration of features, whereas the latent text description is only a broad gesture towards the features that would typically make up an image described in that way. In both decompressions the details are made up, but the far more specific latent image gives much more precise guidance along the way.
A hypothetical world of images
During the training of a model like Stable Diffusion, you could imagine a vast visual universe starting to take form. Every point of this universe is a unique image, and every image is one possible configuration of the ruleset that makes up the model. To visualize this, picture an algorithm that has one end where it takes in text descriptions as inputs and one end where it outputs the images that that text described. Every possible combination of text that we can create has its own unique output image. If we project outwards all of these possible images, we have a hypothetical world of all possible image outputs.
By giving the model a text input, we are instructing it to retrieve the image from this hypothetical world. Through its generation process (that you can find out more about in the article I mentioned earlier), the model manifests these hypothetical images into their ‘actual’ form. The generation process is guided by the compressed form of the text description that was given as an input. The compressed text acts as a set of coordinates to where in this hypothetical space the target image can be found.
The training process is where the model learns the rules that govern our visual expression. The model starts as a more or less arbitrary set of rules. The images that result from applying these rules to compressed text don’t look very image-y. But as the training progresses, this set of rules is constantly updated based on the feedback the model gets on the images it generates. Over hundreds of thousands of training rounds, these rules gradually converge on the reality implied by the images in the model’s training dataset.
Correspondingly, the images that the model outputs get more and more image-y, and provide increasingly faithful visual representations of the text description inputs. As training progresses, the images that make up this hypothetical visual universe inside the model become increasingly in-line with the images that we typically use to express ourselves. Implied by this is not only that the images look more like images, but that the semantic meaning of those images is more accurately mapped out by this space. The way that all of these possible images are mapped out in relation to each other converges with the ways that concepts are mapped out within our minds.
The images that make up the model’s training dataset are like calibration points that guide the construction of this hypothetical image world. Though the record of these individual images is lost, they each take a turn to exert an influence on the overall shaping of this world. If any of these images were focused on too strongly, it would exert too much influence on the construction of this hypothetical image world, making it possible to easily reproduce that exact image, but in the process making it much harder to generate any other.
The spaces in-between
A feature of the one-size-fits-all algorithm that I neglected to mention is that the outputs aren’t constrained to what can be described with words. Though every text input has a corresponding image output, there are far more possible image outputs than there are possible text inputs. This is an extreme case of a picture being worth a thousand words. It’s like this because the space between similar images is vast and filled with images that are even more similar, whereas the space between similar text is also vast, but due to the woefully inadequate number of words in our vocabulary, the ‘text’ occupants of these in-between spaces have to get across their meaning without resorting to words. Though still meaning things in the same way that text typically does, they do so without words.
One way to think about it is to start the hypothetical image world from scratch. Begin with a billion or so calibration images, which are the images that make up the model’s training dataset. Maybe imagine them as stars, which already somehow are laid out according to what they mean. Stars that are more similar to each other are found nearer to each other. These stars are incredibly far apart, but as this image-world starts to take shape the space between these stars is flooded by other possible images. If you now travel from a star to its nearest neighbouring star (which by definition will be the image from the training dataset most similar to it) you will pass by billions of even more similar images that gradually become less like the first star and more like the second star.
If you imagine an inverse text version of this world, where the stars were sentences, these billions of sentences along the way from one star to its nearest neighbour would truly struggle to find the words to convey their extremely subtle differences in meaning. You would perhaps need words not just to specify a colour, or a specific shade of colour, but to specify the fuller context of colour that a specific shade is playing a role in. I suspect I’m understating the problem here, but basically every one of the words we know is surrounded by countless variations of itself that aren’t defined with a word or even string of words. And the in-between sentences of this inverse text world are made up of these ghost-words.
Reaching these in-between spaces
The problem now exists that the space of possible images, which is on the output end of the one-size-fits-all algorithm, is vastly bigger than the space of word-combinations that I can come up with to reach these possible images. One solution would be to work out what the text equivalent would be of images that I want to access. Before the text that a user gives to the model is decompressed into its image form, it first needs to be compressed. The compressed form of text and images in these worlds are recorded as an array of numbers, which function as coordinates to where in this world you would locate the meaning of that text or image. These numbers can be used to indicate a much more specific meaning than words can.
There are many ways of steering the generation process of these models non-verbally, but one that I have used a lot in my experiments has been ‘textual inversion’, which seeks to record the location of a desired concept the model’s hypothetical image space, by finding the corresponding compressed-text equivalent. This means that it tries to find in the sentences in-between what can be expressed with words, one that points to a specific concept in the model’s hypothetical image-world. This wouldn’t be possible with words, but because the sentences are first compressed into an array of numbers, it can shift these numbers around until the image that results from decompressing that array of numbers expresses the meaning that we wanted to convey, but weren’t able to with words.
This array of numbers, which serves as a set of coordinates pointing to the location of that meaning in the model’s hypothetical image space, are recorded as an ‘embedding’. An embedding is simply a record of how/where something is represented inside a model.
Textual inversion
Textual inversion is a ‘fine-tuning’ technique, meaning that it is a form of training done on top of a pre-existing base model, which in this case is Stable Diffusion. The process requires a set of reference images that exhibit a quality or trait that the user wants to record. There are similar, much more popular (and arguably more effective) fine-tuning techniques for Stable Diffusion, such as training ‘Dreambooth’ and ‘LoRA’ models. But I will describe the training process of textual inversion as it provides a clear entry point into thinking about the medium of AI art.
- First, an embedding is created that records either an arbitrary set of coordinates, or the coordinates for a starting phrase that the user provides, such as ‘art’.
- Then, at every round of training (of which there are typically a few thousand) this embedding is decompressed by the model into its image form.
- The resulting image is compared to an image from the set of reference images. A score is calculated of how similar the images are.
- This score is used to update the coordinates recorded by the embedding, shifting them closer to those of the image.
- As the concept mapped by the coordinates increasingly resembles the one occurring across the reference images, the images that result from decompressing the embedding start to share more features with the reference images (i.e. they look increasingly similar)
An aspect of this training process that sheds some light on the medium of AI art is the way that the similarity of images is calculated. The images being compared are in their compressed (latent) form. This means that they exist as a record of a configuration of the features that make up the latent space of the model. It also means that they exist as a set of coordinates to where in the model’s latent space to find that configuration of features.
Feature is a broad term. It can mean anything from the textures, shapes or colours that appear in an image, or a combination of those more basic features into something as complex as the subject matter, the mood implied by the image or even an historical connotation. At the level of these more complex features, they essentially become the building blocks of semantic meaning. These features are the kinds of concepts that we would use to describe an image.
The more similar images are, the more features they will share. A set of coordinates to this space is also a record of what configuration of features is found at that location. If you change the coordinates slightly, the location pointed to by the new coordinates will hold an image composed of a very similar configuration of features. The distance between images is equivalent to how similar they are to each other. The similarity between two images can be calculated based purely on how far apart their respective coordinates are.
It’s the literalness that concepts take on in this space that I think hints at the medium of AI art. It is something so remarkably effective that it remains hidden in plain sight. When users of AI art services aren’t satisfied with the image that they got back from the text description they provided, they change their description. In doing so they steer the generation process towards the image they want. They can’t see the image that they are steering towards, but they know what that image means. To access an image with their preferred meaning, they edit the meaning of their description. This is only possible because of the way that concepts ‘exist’ inside the model.
Using the model as a medium to hold an impression of a novel concept
I like to think of the process of training a textual inversion embedding as tracing out the contours and outlines of a conceptual form within the model. The reference images you choose are the calibration points that guide the training process towards a final conceptual form. Each reference image takes a turn exerting its influence on the form by pulling the overall definition closer to itself.
Here is this artist’s impression of the process:

The line is how the conceptual form is represented within the model. In the first frame it starts off with an arbitrary definition. At each step in training, one of the reference images (the dots) takes a turn to pull this definition towards itself. As more of these steps pass and the definition hones in on whatever concept is shared by the reference images, the pull of the individual reference images at each training step weakens.
The primary use of these training techniques seems to be teaching the model the likeness of the user, so that they can generate fun pictures of themselves in fictional settings or as a fictional character, but with their own face. For that kind of use-case, the reference images need to faithfully represent the concept, which is here the person’s likeness. After enough training the deviation between the reference images falls away and only the shared concept remains. This is why Youtube tutorials will caution you to make sure that the photos that you use are in different settings and with different clothes.
When recording a concept requiring high-fidelity, such as a person’s face or a specific object, any distortion would be unwelcome. Including your own painted self-portraits would be counterproductive. But for artistic concepts you have much more flexibility. Perhaps if you wanted to generate self-portraits that looked more like you than the ones that you actually paint, you could throw in an actual photo of yourself or even a photo that you’ve applied a previously recorded painting concept to. It might work.
Here I depict the learned concepts as outlines*:
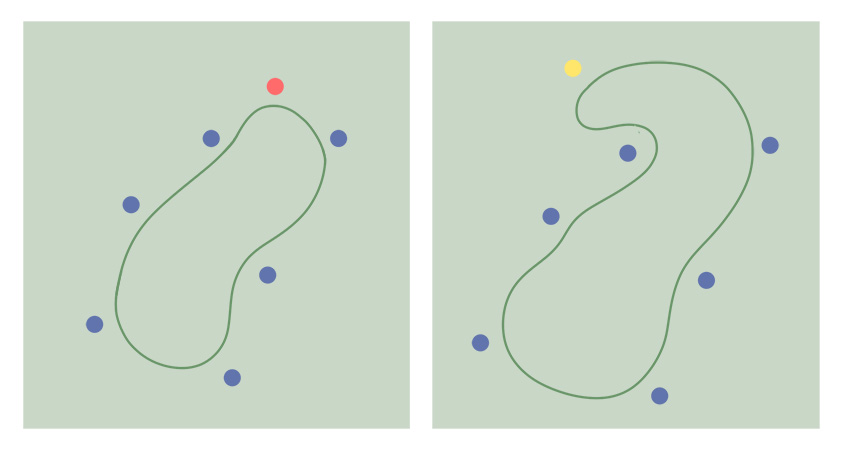
Each frame is the end result of a training run. The green outline is the recorded form of the final conceptual form. And the blue dots are the reference images that both training runs share. The red dot on the left is an image that more or less fits into the concept as defined by the others. But the yellow dot does not fit this concept as well and causes the recorded concept to change noticeably. For a literal concept like an object or a person’s face, this would be an unwanted distortion. But for more artistic application, this distorted conceptual form could be well worth exploring.
Some final comments on the medium of AI art
When I try to get my head around what the medium of AI art is, I find it difficult to find clear boundaries between the different stages of the overall process. The images that the models are trained on are only helpful to the model because they are records of human actions. And these records are only as helpful as meaningful decision-making can be inferred from them. And finally, this decision-making is only meaningful in what it implies about the decision maker.
So what is implied about us? Well, of course the way that we see and describe the world. But what of it? The fundamental stuff of these models, what makes them up, are the patterns that occur across the pixels and text characters that make up their training datasets. Importantly, these patterns are analogous to the ones that occur in our own visual cognition, at least according to the images that we create. The reason that we can record a concept within the model is because the stuff of these images is compatible with the stuff of the model.
The aspect of this medium that I currently find myself most drawn to is the ‘decisions’ part of the process. Once we have a record of our decisions, we can use these models as a medium to hold an impression of whatever version of ourselves can be extrapolated from those decisions. The sets of reference images that I create for fine-tuning the Stable Diffusion model are rich records of my decision-making, saturated with insight into my unique visual language. But there is so much to explore.
The general trend within the development of these tools is towards highly-polished versions of popular styles of digital art. This reflects the desires of the bulk of the users of these tools, who mostly don’t have much artistic background and who ultimately want the images they generate to ‘look good’. Midjourney’s substantial lead in generated image-quality is probably largely due to them successfully incorporating the records that their users create using the service, such as which of their generated images they would like to see in higher resolution.
But there is a trade off made in making these significant improvements to their user’s experience. They are at the same time also tightly constricting the types of outputs that artists can get from their model. When these tools start integrating into professional creative software, quite different trade-offs will be made and I’m sure these tools will evolve in a way that isn’t obvious now. But I suspect that a lot of the improvements made in their commercial application will be at the expense of being able to explore the models as a medium. The more artists there are exploring these models outside of these constrictions, the more we will be able to contribute to the development of tools that are specific to our own needs.